
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 협력필터링
- latent factor model
- implicit feedback
- parameters
- 시간복잡도#기본산술연산#덧셈#곱셈#나눗셈#비트연산
- MLP
- FCN #Fully Convolution #Semantic Segmentation
- tv shows
- nn
- Universal Classifier
- Deep Learning
- 인공신경망 학습
- Collaborative Filtering
- learning a neural network
- neural network
- 알고리즘#수행시간#BigO
- perceptron
- Today
- Total
Study
FCN(Fully Convolutional Networks for Semantic Segmentation) 본문
FCN 논문 리뷰

Semantic segmentation은 pixel 단위로 object가 어디에 있는지를 알아내는 문제라고 생각할 수 있다.
고차원적인 정보를 고려해서 pixel을 분류 -> 서로 다른 좌표(가깝지 않은 좌표)랑 RGB값을 갖더라도 같은 class로 분류될 수 있어야 한다. (Semantic segmentation과 image segmentation과의 차이점)


Semantic segmentation은 pixel 수준의 분류문제를 푸는 것이라고 할 수 있다.
Semantic information에 대한 이해도를 높이기 위해서는 넓은 receptive fields가 필요한데, receptive fields를 넓히려면 pooling을 여러번 하고 layers를 많이 쌓아야 한다. -> 이 과정에서 이미지의 resolution이 점점 줄어드는 문제가 발생
**receptive field란? 어떤 특정 ConvNet feature가 바라보고 있는 input의 영역

semantic segmentation이 Image classification보다 어려운 이유: 공간상의 resolution을 유지해야 하기 때문

픽셀 단위로 classification을 하더라도 classification을 잘 하기 위해서는 결국 이미지 전체를 봐야하는데,
이미지 전체를 보기 위한 방법으로 1. Fully connected layer, 2. Max pooling 이 있다.
그런데 위 두 가지 방법은
1. Fully connected layer는 flatten하면서 위치정보가 사라지기 때문에 semantic segmentation에 부적합,
2. Pooling도 하면 할 수록 resolution이 작아지기 때문에, 원본 이미지 크기와 동일한 output을 생성 불가
라는 단점이 존재한다.
즉, Classification을 잘 하려면 receptive field영역을 넓혀서 이미지 전체를 봐야 하는데, Receptive field를 키우면 output의 resolution이 작아지는 문제가 발생한다.
따라서, 이 trade-off 관계를 해결하는 것이 관건!

해결방법은 Fully connected layer를 제거하고 대신 1x1 Conv layer를 사용하는 것.
FCN = Fully convolution network(말 그대로 처음부터 끝까지 conv layer로 구성된 network)
-> fully connected layer를 제거하고 그 자리에 동일한 역할을 하는 1x1 conv layer를 사용
-> Semantic segmentation이 pixel 단위로 classification 하는 문제이니까, 1x1 filter를 class개수만큼 적용하면 결국 픽셀단위로 fully connected layer를 통과하는것과 동일
-> 결과적으로는 class 개수만큼 input과 resolution이 동일한 score map 얻게 된다.
+ Fully Convolution의 또 다른 장점: 마지막의 fully connected layer가 사라지고 그 자리에 convolution연산이 들어가니까 어떤 사이즈의 Input image가 들어와도 shape 오류가 발생하지 않고 input size에 맞는 output이 나오게 된다.


Fully connected layer를 1x1 convolutional layer로 대체함으로써 feature map이 flatten되는 문제는 해결했는데, 많은 pooling을 거치면서 원래 input image에 비해 dimension이 많이 줄어든 문제는 아직 미해결.
-> upsamping을 통해 원래 이미지 사이즈로 되돌리자!
FCN논문에서 사용한 upsampling 방식은 bilinear interpolation과 Deconvolution
1. Bilinear interpolation


Interpolation(보간)이란 알려진 지점의 값 사이(중간)에 위치한 값을 알려진 값으로부터 추정하는 것.
(Interpolation과 대비되는 용어로 extrapolation이 있는데, extrapolation은 알려진 값들 사이의 값이 아닌 범위를 벗어난 외부의 위치에서의 값을 추정하는 것을 말함)
예를 들어, 어떤 사람이 20살일때 키와 40살에서의 키를 보고 30살에서의 키를 추측하는 것은 interpolation이고, 과거 1살때부터 현재 나이까지의 키를 보고 앞으로 10년 후의 키를 예측하는 것은 extrapolation이다.
선형 보간법(linear interpolation)은 두 지점 사이의 값을 추정할 때 그 값을 두 지점과의 직선 거리에 따라 선형적으로 결정하는 방법.
그리고 Bilinear interpolation은 우리 말로 적자면 쌍선형 보간법, 또는 이중선형 보간법으로 1차원에서의 선형 보간법을 2차원으로 확장한 것이다.
2. Deconvolution
논문에서는 Deconvolution이라고 부르지만, transpose convolution이라고 불러야한다는 사람이 많다.
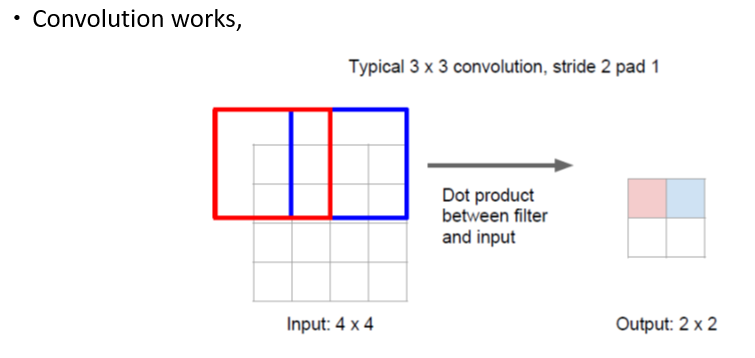

Deconvolution은 convolution을 거꾸로 하는거라고 생각하면 쉽다.
Convolution했을 때와 동일한 설정(동일한 filter size, stride, padding)을 적용하되, 대신 거꾸로
Input의 값 하나하나(scalar값)를 filter에 broadcast해준 뒤, 거기에 convolution할 때와 동일한 stride와 padding을 적용해서 차원을 늘린다.(겹치는 영역은 sum)


위 그림은 Deconvolution을 transpose convolution이라고 부르는 이유.

어떻게 네트워크를 학습시켰을까?
-> classification을 위해 pre-train되어있는 모델을 가져와서, 가장 뒤에 있는 fully connected layer를 떼고 1x1 conv layer(channel dimension은 12)랑 deconvolution layer를 붙여서 네트워크 구성.
-> Pre-trained된 모델 중에 어떤 모델이 가장 성능이 좋은지 비교하기 위해서 PASCAL 2011 데이터의 validation set 사용.
-> 논문에서는 vgg16이랑 vgg19랑 성능 상의 차이가 없어서 더 파라미터 수가 적은 VGG16으로 했다고 한다.
-> 구글넷같은 경우는 final loss layer만 썼고, 성능향상을 위해 마지막에 average pooling 하는 layer는 버리고 테스트
결론: 성능 비교해보니 구글넷보다도 vgg가 더 나아서 논문에서는 vgg구조를 기준으로 설명

픽셀단위로 classification을 하더라도 이미지 전체를 보는게 좋은데, 이미지 전체를 보기위해서 receptive field를 늘리면 output 의 resolution이 점점 줄어들어서 줄어든 feature map의 사이즈를 다시 원래 이미지의 크기로 복원시키면 prediction의 결과의 경계가 모호해지는 문제가 발생한다.(FCN-32s prediction 결과를 참고)
-> 경계를 더 분명하게 만들기 위해서 skip connection을 적용
Skip connection이란? lower layer에서 얻은 prediction이랑 higer layer에서 얻은 prediction을 결합해서 좀 더 정교한 prediction을 하는 것.
(lower layer에서 나온 feature맵을 그 뒤의 layer는 skip시켜버리고 나중에 결과들을 sum해서 이름이 skip connection...)
Lower layer에서부터 얻은 activation map은 higher layer에 비해서 좀더 공간적인 정보가 잘 보존되어 있고, higher layer로부터 얻은 map은 이미지 전반적인 정보(global information)이 더 많기 때문에 다 함께 고려하면 좋을것이다! 라는 아이디어

그럼 lower layer로부터 얻은 score map이랑 higher layer로부터 얻은 score map을 어떻게 같이 고려할까?
1. 이전의 layer로부터 얻은 score map을 x2배로 upsamling 해준다.
2. 현재 layer로부터 얻은 feature map을 1x1 conv를 통과시켜 classification을 진행하고 score map을 얻는다.
3. 이 두 score map을 sum한다.
4. Sum한 score map을 원래이미지 size로 upsampling한다. (현재 score map의 크기가 원본이미지의 1/32이면 32배를, 1/16이면 16배를 ...이런식으로)
중간에 끼어있는 upsampling layer는 초기화만 bilinear interpolation으로 하고 그 뒤로는 weights 학습.
마지막 deconvolution filter는 그냥 bilinear interpolation으로 고정.

skip connection을 어디까지 적용했느냐에 따라 성능의 차이를 확인할 수 있다. 단, stride 8 이전의 layer는 skip connection을 적용해도 성능 개선에 별 영향을 끼치지 못해서 적용하지 않았다고 한다.

